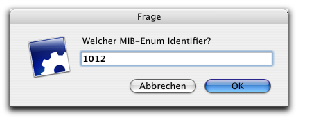
Business OPEN v11 wird standardmäßig im sogenannten Unicode-Modus ausgeliefert.
|
Unicode ist ein internationaler Standard, in dem langfristig für jedes sinntragende Schriftzeichen oder Textelement aller bekannten Schriftkulturen und Zeichensysteme ein digitaler Code festgelegt wird. Während herkömmliche Computer-Zeichencodes wie der ASCII-Standard oder ISO 8859-1 nur einen begrenzten Vorrat an Zeichen umfassen, wird Unicode laufend um Zeichen weiterer Schriftsysteme ergänzt. ISO 10646 ist die von ISO verwendete, praktisch bedeutungsgleiche Bezeichnung des Unicode-Zeichensatzes; er wird dort als Universal Character Set (UCS) bezeichnet. Mehr Info: http://de.wikipedia.org/wiki/Unicode |
Gibt es weitere Vorteile von Unicode?
|
Unicode ist zukunftssicher (siehe oben "Vorrat an Zeichen"). |
|
|
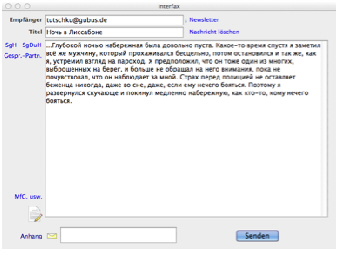
Textfelder können im Unicode-Modus bis zu 2 GB Zeicheninhalt aufnehmen (bisher 32 KB). |
Gibt es Problembereiche in BO v11 Unicode?
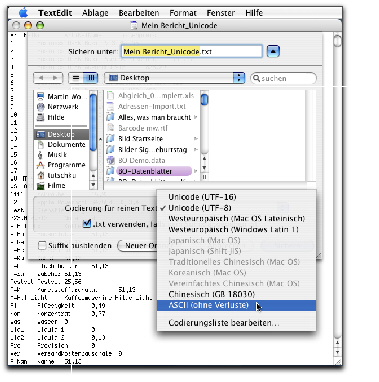
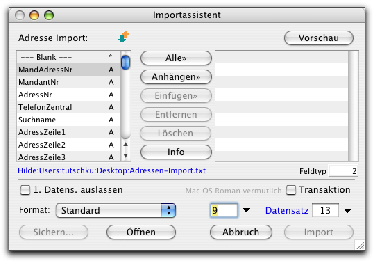
Der Austausch mit externen Anwendungen via Import/Export verlangt in BO v11 Unicode größeres Augenmerk als in früheren BO-Versionen.
1. Import mit dem BO Import-Assistenten
2. Export mit dem BO Export-Assistenten oder 4D Report

|
TextWrangler kann unter folgendem Link kostenlos heruntergeladen werden: http://www.barebones.com/products/textwrangler/ |
| Kapitel-Hauptseite | Zurückblättern | Weiterblättern | BO-Doku Startseite |